Introduction
Machine learning has made remarkable progress in the last years, yet its success has been overshadowed by different attacks that can thwart its correct operation. While a large body of research has studied attacks against learning algorithms, vulnerabilities in the preprocessing for machine learning have received little attention so far.
Image-scaling attacks allow an adversary to manipulate images unnoticeably, such that they change their content after downscaling. Such attacks are a considerable threat, as scaling as pre-processing step is omnipresent in computer vision. Moreover, these attacks are agnostic to the learning model, features, and training data, affecting any learning-based system operating on images.
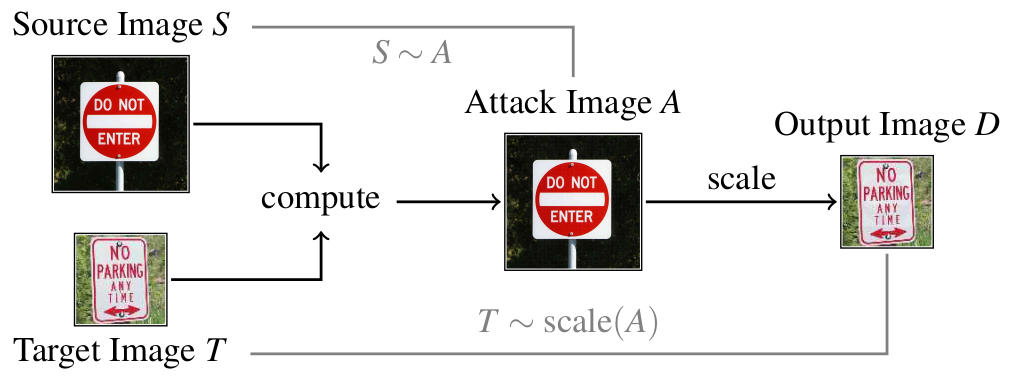
Take, for instance, the example above. The adversary can take an arbitrary source image, here a do-not-enter sign, and a no-parking sign as target image. The attack generates an image A by slightly changing the source image. This attack image still looks like the source image. However, if this attack image is downscaled later, we will obtain an output image that looks like the target image. This output image is then passed to a machine learning system. So while we see the source image, the ML system obtains the target image. This allows a variety of attacks that we discuss below.
All in all, scaling attacks have a severe impact on the security of ML, and are simple to realize in practice with common libraries like TensorFlow. Our work provides the first comprehensive analysis of these attacks, including a root-cause analysis and effective defenses.